Modern infrastructures are no longer confined to on-premises servers alone. Instead, they span cloud environments, containers, microservices, and globally distributed systems. This landscape, known as a hybrid cloud environment, has become the new norm for organizations, primarily because it offers the scalability of the cloud and ownership over specific elements afforded by an on-premises setup.
As you can probably guess, with this flexibility comes complexity. Monitoring this complex yet flexible and disturbed setup introduces a unique set of challenges, from fragmented visibility and inconsistent performance to potential security gaps. As organizations continue to scale, visibility is no longer optional or a luxury—it should be considered a foundational aspect.
Key points of the article:
- To effectively manage your hybrid cloud environment, you need to track, analyze, and visualize the performance, availability, and health of your services, systems, and applications. This will help you gain comprehensive visibility and detect issues early.
- By using metrics, logs, and traces, you can gain deeper insights into your hybrid cloud environment, enabling you to proactively identify and resolve problems. Therefore, observability is crucial for understanding why issues occur.
- To optimize your hybrid cloud monitoring, follow these best practices: understand your landscape and business needs, automate monitoring workflows, strengthen security and compliance, set cloud governance measures, optimize cost management, implement disaster recovery, document everything, and continuously monitor and optimize.
- Ensure your hybrid cloud monitoring strategy includes comprehensive and unified visibility, automated discovery with contextual and consistent tagging, security monitoring and compliance reporting, cost management, disaster recovery, documentation, continuous monitoring, optimization, standardization, and correlation of metrics across environments.
- SolarWinds Observability Self-Hosted, provides deep visibility and real-time insights, Datadog offers comprehensive monitoring and support for both on-premises and cloud environments, and LogicMonitor ensures unified visibility and efficient operations. Consider using these top hybrid cloud monitoring tools for 2025.
What Is Infrastructure Monitoring and Why Is It Mission-Critical in the New Normal?
Hybrid cloud environments are built on top of core infrastructure components. This core infrastructure component is often a mix of on-premises and cloud components, which could be public or private clouds. These components rely on computer storage, network, and application layers that need to be reliable and efficient to keep the lights on.
Infrastructure monitoring is a critical discipline that tracks and collects data about the health, performance, and availability of these components and your underlying systems and applications. “Systems and applications” means your servers, VMs, containers, databases, and other back-end components within your tech stack. By tracking these systems, infrastructure monitoring provides real-time visibility, enabling you to proactively detect, resolve, and identify issues before they impact users, and fix issues after they are affected.
Without solid infrastructure monitoring, you can’t:
- Know if your cloud-native app is overloaded
- Tell if a VM in your private cloud is failing silently
- Know when there is a network latency between on-prem systems and cloud-hosted services
Now, How Does This Work?
Traditionally, infrastructure monitoring was built around static, on-premises servers. However, with the rise of cloud infrastructure, a shift has been necessary, as servers can now be spun up or torn down on demand. This means engineering teams have had to start monitoring components that exist only temporarily, also known as ephemeral infrastructure.
Monitoring no longer stops at individual hosts but expands to logical groupings, such as all instances within a region or availability zone. This visibility needs to span across your hardware layer (physical resources such as CPU, memory, and disk health), your OS layer (monitors how the OS allocates resources and runs processes), and lastly, your application server layer (how back-end services respond to requests and manage workloads).
Today, monitoring typically starts with a lightweight software agent. An agent is a type of software installed by the engineer on their host, which can be physical servers, bare metal servers, or VMs. The agent recognizes the running application and logs all information you can use for your infrastructure metrics, such as CPU usage, memory consumption, uptime, availability, network traffic, and disk I/O.
This data then goes to a centralized monitoring platform for processing, analysis, and visualization through dashboards, alerts, and reports. But as infrastructure continues to evolve, so do the organization’s monitoring strategies. Organizations no longer operate solely in traditional data centers or the cloud; most adopt hybrid environments that combine on-premises systems with multiple public and private cloud services.
This new shift brings us to the next topic: hybrid cloud monitoring, where achieving unified visibility across all these environments is the major pain point. At the end of the day, infrastructure monitoring isn’t only about collecting data but about making sense of your metrics in real time across diverse systems.
What Is Hybrid Cloud Monitoring?
Hybrid cloud monitoring tracks, analyzes, and visualizes the performance, availability, and health of your services, systems, and applications running on your on-premises and public/private cloud infrastructures. This process involves using specialized tools and techniques to collect real-time data while following best practices to track and analyze the health of your workloads running on-premises or in the cloud. This allows organizations to scale with little overhead costs.
By monitoring the applications and services within their hybrid cloud environment, organizations can gain comprehensive visibility, insights, and early detection of issues to achieve an optimized, secure, and reliable environment for their assets.
Differences Between Hybrid Cloud and Multi-Cloud Monitoring
The benefits of flexibility, scalability, and cost efficiency drove the adoption of the cloud environment. These benefits have led many organizations to integrate their existing on-premises infrastructure with cloud services, thereby leveraging both benefits.
However, it’s crucial to recognize the different types of cloud strategies, which differ in terms of monitoring.
|
Hybrid cloud monitoring |
Multi-cloud monitoring |
|
|
What is it? |
Monitoring of hybrid cloud assets, which involves using resources both on-prem and in the cloud (public and private) |
Monitoring of multi-cloud assets, which involves using resources across multiple public cloud environments managed by multiple cloud providers |
|
Infrastructure scope |
Combines local data centers with cloud services |
Combines services from different cloud vendors only |
|
Complexity |
Comes from bridging different deployment environments (on-prem and cloud) |
Comes from bridging monitoring and standardization of metrics from different cloud platforms and services |
|
Security considerations |
Must consider on-prem security and cloud security policies |
Must consider different security policies and protocols across multiple clouds |
|
Tool requirements |
Must support and allow monitoring of on-prem and cloud integration |
Must support integration across multiple cloud platforms, thus cloud-agnostic tools |
|
Ideal users |
Organizations looking to explore cloud deployment without migrating from their on-prem legacy systems |
Organizations using the cloud but who want to avoid vendor lock-in |
Each cloud strategy has its own benefits and challenges. Organizations need to carefully consider their requirements before choosing a cloud strategy.
The Role of Observability in Hybrid Cloud Monitoring
We can’t discuss hybrid cloud monitoring without considering observability. Observability extends beyond traditional monitoring, which informs you that something is wrong and sometimes where, but never provides the underlying cause and, at times, can’t pinpoint the exact location of the issue.
There are three pillars of observability, each providing a distinct yet complementary layer of insight into one’s environment.
- Metrics offer quantitative data points, so they can be used to detect anomalies or performance degradation at a glance.
- Logs provide detailed and timestamped records of system events, application behaviors, and user activities. This is particularly useful when diagnosing issues, conducting audits, and understanding system changes over time.
- Traces track a request’s entire life cycle as it travels across multiple services and systems, highlighting dependencies and pinpointing latency or failure points in complex workflows.
Together, these three pillars provide deep visibility into your infrastructure environments and make it relatively easy to monitor your setup proactively.
Essential Components for a Hybrid Cloud Monitoring Strategy
A successful hybrid cloud monitoring strategy requires more than your setup. You need an actionable, clear, and detailed strategy in place to effectively capture what is really going on.
1. Comprehensive and Unified Visibility
You need visibility across your on-prem and cloud environments. Achieving this requires consolidating data, logs, and traces from both environments, utilizing a tool that supports both seamlessly, and integrating them effectively, as this is necessary when scaling.
Once you have these, you must standardize your metrics across environments and have a comprehensive dashboard for proactive detection and alerting. Remember, the goal is to have achieved full observability, not partial snapshots. Thus, your strategy should incorporate all three pillars of observability. Monitoring and collecting these components will ensure you can proactively detect issues and identify their root cause. You’ll need to define and configure key performance indicators (KPIs) for your system, enable real-time alerting, and implement automated remediation workflows to handle any issue.
2. Automated Discovery With Contextual and Consistent Tagging
Since you have a fairly distributed environment, to avoid fragmented monitoring, you need to tag your components with metadata such as region/zone, service name, environment, owner, and application. This will make grouping, filtering, alerting, and cost tracking across your infrastructure less challenging since resources are constantly spun up and down. You need to figure out how to detect new hosts, remove decommissioned resources, and apply standard monitoring configurations automatically.
Tools such as SolarWinds Observability Self-Hosted can scan your environment, discover access, and generate dynamic topology maps to visualize your landscape and prevent blind spots.
3. Security Monitoring and Compliance Reporting
The more diverse your environment, the greater the risk and likelihood of threats. Thus, ensure continuous monitoring for vulnerabilities and misconfigurations, implement identity and access monitoring, and log everything, as these results are handy during troubleshooting. On the compliance side, you must continuously validate that your setups meet regulatory requirements. Thus, you need to automate compliance checks and set real-time alerts for violations.
What Are the Best Practices for Hybrid Cloud Monitoring?
Adhering to best practices when implementing hybrid cloud monitoring is crucial for achieving optimal performance and ensuring everything operates as intended.
1. Understand Your Landscape and Business Needs
Before developing any monitoring strategy, the first step is to understand the business’s infrastructure configuration and establish a comprehensive baseline.
What does your day-to-workload and application’s health look like? Where are your infrastructure, data, applications, and network connections? How do each system’s performance needs, data sensitivity, and compliance requirements differ? How does your workload function? You can’t and shouldn’t dive into monitoring without fully understanding your existing infrastructure.
You can start by mapping out your current infrastructure using an application performance monitoring (APM) tool, such as SolarWinds Observability Self-Hosted. This will help you determine what workloads you need to migrate to the cloud and what can and shouldn’t be based on performance, security, and compliance requirements.
2. Automate Monitoring Workflows
Your environment has cloud resources now, and one aspect of this environment is that resources are created and destroyed dynamically. Thus, manual configuration wouldn’t work efficiently!
You need to automate your workloads. Automation ensures consistent, fast, and error-free operations. You can start by integrating monitoring with your continuous integration/continuous delivery pipeline during deployments and using auto-discovery features to detect and monitor any VMs or containers created. It’s also important to set up automated alerting accompanied by automated responses so that a notification gets sent out if any thresholds are breached and resources can be reallocated.
3. Strengthen Security and Compliance and Set Cloud Governance Measures
Compliance, governance, and security in a hybrid cloud landscape are tricky because different compliance standards, such as the Health Insurance Portability and Accountability Act and the General Data Protection Regulation, govern each environment. Understanding the compliance standards that govern your environment and business is important. One way you can maintain security is by operating a zero-trust security model, which believes every request should be verified to reduce the risk of breaches and threats.
It’s also important to tag your data appropriately and store it based on its kind and sensitivity. Lastly, use role-based access control (RBAC) to restrict access to sensitive data and measures, such as multifactor authentication and encryption, to add a security layer to your data.
4. Optimize Cost Management
One reason why organizations explore the cloud route is to save overhead costs. However, more often than not, organizations realize that when they explore the cloud, it can become expensive quickly. The bill can escalate due to improper resource management, particularly with auto-scaling and pay-as-you-go billing. Therefore, you must establish thresholds and monitor cost-related metrics, including instance usage and idle time. Lastly, depending on your cloud service provider, use cost-monitoring tools such as AWS Cost Explorer or Azure Cost Management to help you identify areas to cut back.
5. Implement Disaster Recovery
Disaster recovery is more than saving your data and backups. You need to have a plan for when anything goes wrong. What happens when there is downtime? Can you recover sensitive data quickly and accurately? Are there automatic failover systems so that your other environment can step in if your private cloud goes down? You must consider all these factors. Lastly, it’s also important to test your disaster recovery plan to identify any necessary changes and ensure it remains operational.
6. Document Everything
A hybrid cloud setup has many moving parts, which is why documentation is important. It’ll help during troubleshooting, knowledge sharing, and training while ensuring consistency across configurations, processes, alert policies, and procedures.
Since documentation isn’t a one-time task, it’s also essential to regularly update it to reflect any changes in the environment or monitoring practices.
7. Continuously Monitor and Optimize
Monitoring is a continuous activity. As your infrastructure grows, your monitoring setup needs to be modified to accommodate the changes.
Regularly review alerts and thresholds to minimize false positives. Monitor and track changes to ensure your service level agreements are updated to reflect the current state of your environment. This will allow you to adjust expectations and modify your KPIs.
8. Standardize and Correlate Metrics Across Environments
Each environment has its own metrics. If you don’t standardize these metrics, it’ll be challenging to correlate performance across these systems and gain comprehensive visibility into your landscape.
Start by defining the metrics that matter to you. Metrics such as latency, cost efficiency, availability, resource usage, and utilization are great places to start. Remember to use the same measurement unit across the board, set a baseline, and adjust as your environment changes. Lastly, select an integrated monitoring tool that supports metric correlation and anomaly detection across environments, providing a single dashboard view of your metrics.
9. Pick the Right Tool
Hybrid cloud environments involve utilizing resources from both on-prem and cloud infrastructure setups. Your cloud setup may involve multiple platforms and service providers. To avoid siloing in your monitoring, select a tool that supports multi-environment visibility and offers native integrations across cloud providers and virtualization technologies. This will also lead to easier troubleshooting.
How do you Choose the Right Cloud Monitoring Tool for Hybrid Environments?
Several factors should be considered when selecting a tool for your organization. While cost and features are important, it’s crucial to select a proactive tool compatible with your hybrid cloud environment.
Here are a few considerations when selecting a tool for your organization.
1. Monitoring Capabilities of the Tool
The ideal tool should be able to comprehensively monitor resources, track key metrics, and quickly identify performance bottlenecks while optimizing resource allocation. Thus, it’s essential to monitor your tool’s capabilities to ensure it can track all the metrics you need to gain insights.
So, what should you consider when evaluating monitoring capabilities?
Can it capture response times, error rates, and transaction traces? How effective is it when it comes to log management and real-time analysis? These are important for uncovering operational issues. Does it support containerized workloads and serverless architectures? How are the tool’s native cloud provider integrations capabilities? Does it have broad multi-cloud support? Additionally, look for automation and orchestration features such as auto-scaling, self-healing, and workload balancing, as these can help minimize your manual overhead.
Lastly, does it have AI-powered capabilities? These features will help you correlate performance data across your entire stack, providing complete visibility to pinpoint and resolve issues quickly.
2. Alerts and Notifications
Your tool needs to do more than collect data. It needs to flag any anomalies proactively, the moment they arise, and assist your team in resolving issues before they become incidents. Choose a tool that offers advanced alerting systems, where thresholds and triggers can be finely customized, so you receive the alerts that truly matter. You can take this further by checking if your tool of choice can integrate with communication platforms, such as Slack or Microsoft Teams, as this will ensure the alerts get dropped off right at your doorstep.
3. Data Visualization and Reporting
The usability of the data visualization and reporting tool is as important as its technical capabilities. A well-designed, intuitive dashboard displaying comprehensive details will enable your team to monitor metrics without a steep learning curve. A highly customizable dashboard would be a plus, as it would allow you to optimize its intuitiveness. Your dashboard should work in real time with access to historical data, allowing you to spot trends, diagnose root causes, and make prompt, informed decisions when it matters most. Strong reporting and data export capabilities are essential for sharing insights across teams and meeting compliance requirements.
4. Security
Security should always be a top priority when selecting a cloud monitoring tool, especially for hybrid environments spanning multiple platforms and data centers. You need to ensure your tool offers robust security features, from RBAC to data encryption, and has the proper compliance certifications to back it up. This will ensure the organization’s data is safe from unauthorized access or breaches.
5. Resources With a Responsive and Supportive Community
Access to support and learning resources with a strong community or vendor ecosystem is often overlooked. To get the most from your monitoring investment, choose a solution that offers comprehensive documentation, active user forums, and a responsive support team. These features are invaluable when incidents occur, as they can significantly reduce troubleshooting time and accelerate onboarding.
Top Cloud Monitoring Tools in 2025
There are several hybrid cloud monitoring tools available, but I’ll cover my top three for enterprise solutions. If you’re looking for a free or open-source solution, there are also many available to download. For a professional setting, however, I recommend a solution designed for the enterprise environment.
Managing monitoring in hybrid cloud environments can be complex, with systems spread across on-premises servers, private clouds, and sometimes multiple public clouds. Organizations require a solution that offers deep visibility, real-time insights, and simplified operations to navigate this complexity.
Below are some top hybrid cloud monitoring tools to consider in 2025.
SolarWinds Observability Self-Hosted
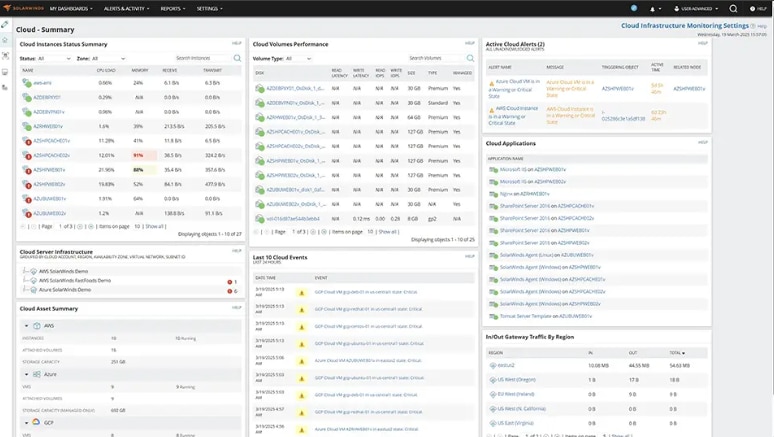
A great recommendation is SolarWinds Observability Self-Hosted, a scalable, cloud-native solution designed to monitor hybrid cloud infrastructures in real time. It focuses on full-stack observability, enabling organizations to track and gain insights into the health of their applications and identify potential bottlenecks across diverse environments.
Its agentless monitoring allows users to track applications and services on-prem or in the cloud. It also has a powerful dashboard that enables users to identify issues, overlay, and correlate different performance metrics. With preconfigured templates and customization options, SolarWinds Observability Self-Hosted allows quick deployment and tailored monitoring for hybrid cloud environments.
SolarWinds Observability Self-Hosted offers all of these on one platform, meaning you don’t need multiple tools to get visibility across stack layers.
Datadog Cloud Monitoring
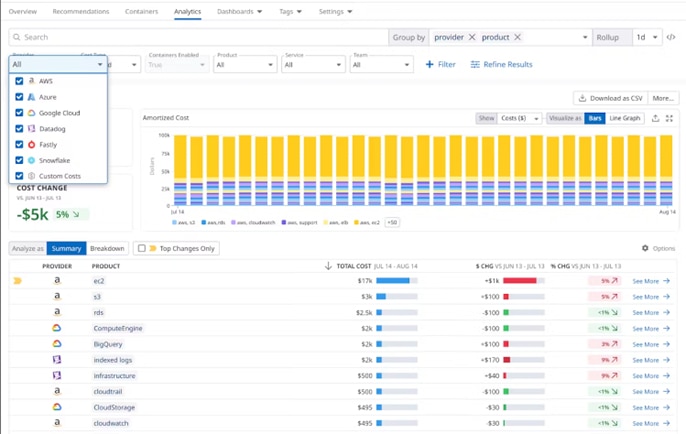
Datadog is great because it is designed for the cloud. This tool collects and analyzes data from various services across your cloud environment, thus giving DevOps and engineering teams a comprehensive and real-time view of their technology stack. Similarly, like the other tools on the list, Datadog comes with log management and customizable dashboards for APM and anomaly detection.
As a fully SaaS-delivered solution, Datadog boasts numerous deep native integrations and excels in a cloud environment where granular application performance tracing and dynamic scaling are top priorities.
LogicMonitor
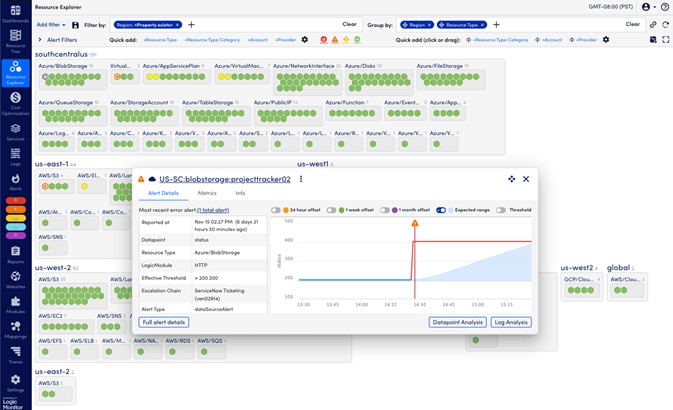
Through its SaaS-based platform, LM Envision, LogicMonitor delivers hybrid observability built to unify the monitoring of your hybrid environment. This tool features intelligent discovery protocols, providing real-time operational visibility, dynamic topology mapping, intelligent alerting, and root cause analysis. It works best for organizations that need a fast and scalable way to gain comprehensive insight across hybrid environments. Our favorite LogicMonitor feature is that it’s not vendor-agnostic and doesn’t require heavy agent deployments.
SolarWinds Server & Application Monitor
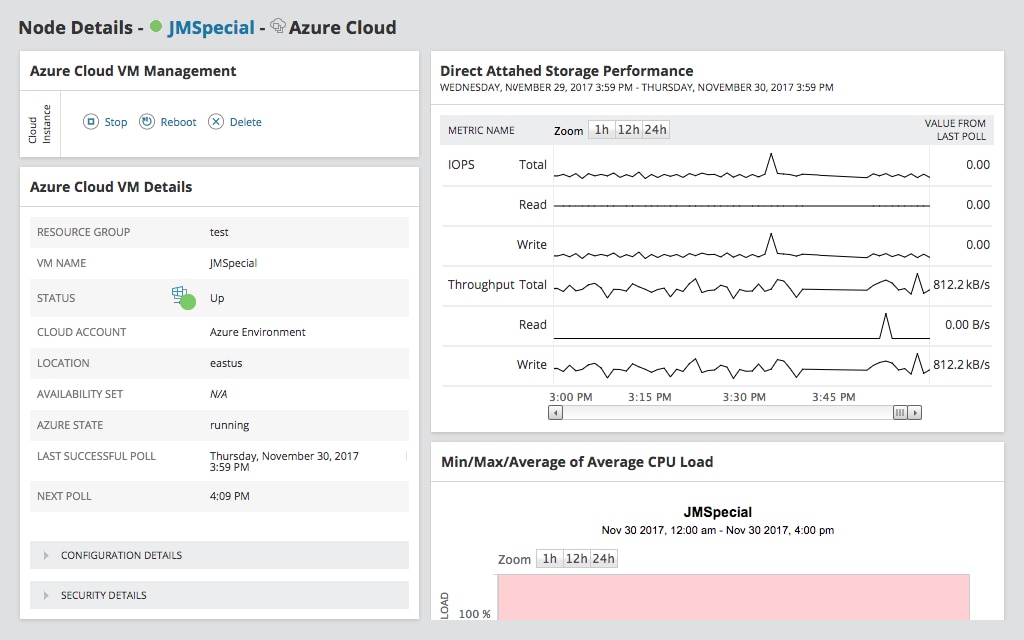
My top choice for hybrid cloud monitoring solutions is SolarWinds Server & Application Monitor (often referred to as SAM). it provides end-to-end monitoring and visibility into your applications, whether they’re on a public or private cloud, or within a hybrid cloud infrastructure. With agentless monitoring technology, applications and services can also be monitored on-premises, or with cloud providers such as AWS, Microsoft Azure, and others. Even if your applications move between the cloud and on-premises, you can keep track of them using SAM.
It also includes features recognizing the importance of synthesizing multiple different data types when troubleshooting within a hybrid cloud environment. It includes a dashboard called PerfStack™ to help you deal with this issue. PerfStack allows you to drag and drop different hybrid cloud performance metrics into the tool, and then it displays them in an overlaid analysis, so you can see the connections between different metrics and correlate problems or chains of issues. If response times are slow or you’re dealing with packet loss or issues in dependent connections, SAM can also help you get to the bottom of this and figure out which part of your IT infrastructure is affecting application performance.
Finally, SAM also includes metrics and monitoring for your application health and performance and monitoring from out-of-the-box templates. It’s built to make it easy to get started, so you can quickly determine how your hybrid cloud is performing. You can also use SAM for hybrid cloud monitoring with custom applications, and you can modify the out-of-the-box templates or create new ones to fit your needs.
SolarWinds SAM also includes a free trial for up to 30 days, so you can test it out and see how it works.
BMC TrueSight Operations Management
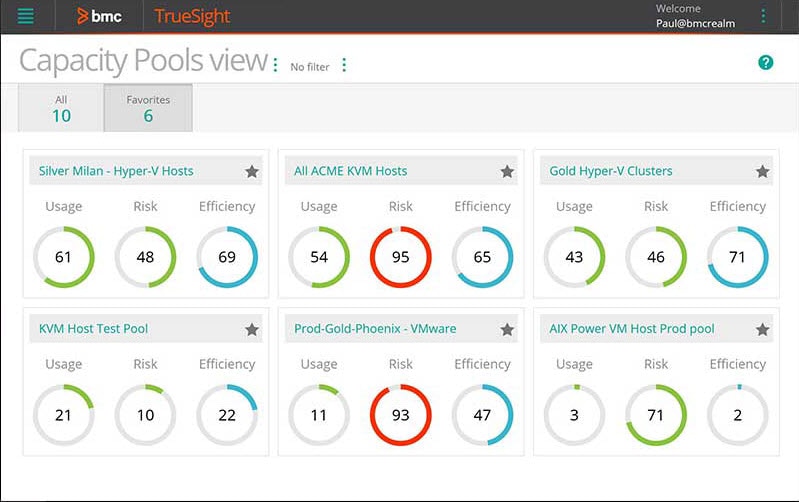
I also recommend looking at BMC products and for hybrid cloud monitoring check out TrueSight Operations Management in particular. This is a tool driven by machine learning and AIOps, and it monitors and analyzes your system to learn typical behavior, correlate data, and help you to find and predict issues to fix them fast. One of the great things about the machine learning process is it can reduce event noise, identify data anomalies, and provide predictive analytics, so you can remedy problems before it impacts your business users.
It also includes tools for log analytics and some kinds of automated remediation, so small and uncomplicated issues can be resolved quickly. This reduces your overall mean time to resolution. It works with hybrid environments and monitors infrastructure performance across on-premises or cloud systems, and hybrid cloud infrastructure as well.
While this isn’t a tool designed for hybrid cloud environments, BMC also offers several other products you can use in combination with TrueSight Operations Management. This can give you a complete monitoring solution to ensure your hybrid cloud is performing as well as possible.
Conclusion
The best time to take hybrid cloud monitoring seriously was yesterday; the second-best time is now. Ignoring or delaying a solid monitoring foundation will only lead to performance issues, outages, downtime, and security risks later on, especially since your environment is so diverse.
The good news is that it’s never too late to get started and begin gaining insights into what is happening across your environment. The key is knowing where to start and having the right tools and best practices to help you take a resilient and scalable approach.
This post was written by Ifeanyi Benedict Iheagwara. Ifeanyi is a data analyst, machine learning engineer, and Power Platform developer who is passionate about technical writing, contributing to open-source organizations, and building communities. Ifeanyi writes about machine learning, data science, and DevOps, and enjoys contributing to open-source projects and the global ecosystem in any capacity.
