
Until recently, performance certainty has mostly been left in the hands of a system’s makeup and its database administrator’s work ethic. Ever since the idea of virtually always-online file storage database management systems (DBMS) passed with corporate leaders, uptime has been assumed. Amazon, Google, and other cloud infrastructure providers became the go-to guys. Uptime became less of an issue and performance became “the new black.”
However, you can’t hope for performance. You need to be certain of the system’s performance. You need to know what drives performance and how changes to the system may affect the performance profile. In summary, this is what performance certainty means.
The goal of this post is to lay out the strategic ways through which you can make sure performance isn’t left to chance—or the specs of the deployment environment. I’ll suggest some tools to make sure the changes you make when no one is watching (when the work is really happening) are seen for the impact they bring.

It’s a New World, Performance Matters
Not long ago, operations teams were focused on system or subsystem uptime. Today, the focus has shifted to applications and application performance, and this focus is reflected in two areas: end-user experience and system efficiency.
In the cloud and in the world of chargebacks, there’s a more obvious correlation between performance, resource utilization, and cost. For some companies, especially software as a service (SaaS) startups, infrastructure costs represent a significant percentage of their expenses. Therefore, system performance can have a direct impact on company profitability, health, and sustainability.
We’ve Been Operating Without Performance Certainty
Operations teams too often base decisions on estimations and hope. They don’t do this because they want to operate this way but because they have no choice. Let me illustrate with two examples:
The first one involves databases and virtualization. For many years, database administrators (DBAs) resisted moving databases to virtualized environments because of the uncertainty about how a database server would perform in a virtual machine (VM). They were uncomfortable with the potential performance impact of running on a hypervisor versus running on bare metal, and they were uncomfortable with the new metrics and operational unknowns of optimizing a VM.
There was no performance certainty.
Today, 80% of databases run in virtual environments. In 2015, Amazon shared publicly they’re making a billion dollars a year on database as a system (DBaaS) software (RDS, Aurora, Dynamo, etc.), not including the databases running on EC2 instances. Since they’re now in a dynamic environment, performance can change at any time—when there’s a noisy neighbor, when an administrator moves the database to another VM, etc.
The second example is a personal story. When I was working at one of the top cloud service providers, I helped a customer operate a SaaS application. They told us they added a cluster every time they launched a certain number of customers, and I asked them why.
The customer said this model was working. I asked what the driver of performance was—maybe we could help them double the number of customers every cluster could handle. Was it because the cluster ran out of memory, database performance, storage space, or something else? The customer didn’t know. All they knew was what worked, and they didn’t have the time to experiment or the visibility to know what drove performance and where their bottlenecks were.
With so many changes and so many variables, the old way of figuring this out—trial and error—doesn’t work anymore. What we need (and what the business expects from our systems) is performance certainty.
Performance Visibility Is a Prerequisite for Performance Certainty
Systems are dynamic and constantly changing. You move VMs around, replace hosts, add applications to the storage system, load changes in each application, and more. Take the ongoing shifts to flash-based storage systems, converged architectures, and migration to cloud as examples. It’s important to have a baseline of performance and understand how much each component impacts performance.
The seven DevOps principles establish not only a performance orientation but the requirement to monitor everything to get the needed cross-team visibility into how every change impacts the system from a performance and throughput perspective.

You can’t fix what you can’t see. Before talking to finance about an AFA storage device, you should know exactly how much your existing storage system is contributing to performance and how the shift to faster storage will improve performance in terms of resource utilization and end-user experience.
Before you move your next workload to the cloud, you must understand the key aspects of the system capable of impacting performance and have a reasonable expectation of how they’ll perform in the cloud, what resources they’ll need, and how much those resources will cost per hour.
Seven Steps to Achieving Performance Certainty
So how do you get performance certainty? Here are a few ideas, each of which will take you one step closer:
- Embrace performance as a discipline. Uptime should no longer be the key metric you use to measure the quality of work. Uptime is assumed. How fast can you make the system work? How often do the teams talk about performance? What tools do you have to understand and improve performance?
- Adopt a response-time analysis Your focus must shift from resource metrics, logs, and health to time. This includes time spent on every process, query, wait state, and contribution to time from storage (I/O, latency), networking, and other components supporting the database and the application. Here’s how response time applies to database performance.
- Establish a baseline. Define the key metrics; ideally, they should be centered around application throughput and end-user experience (again, not CPU utilization or theoretical IOPS). Statistical baselines help you understand what’s normal and how/when performance changes. Alerts based on baselines (which are dependent on relevant performance metrics) then allow you to focus on what matters.
- Don’t guess. Before moving to faster hardware or provisioning more, understand the performance contribution of each component, which indicates its potential contribution to performance improvement.
- Become the performance guru of your team. Knowledge is power. With the shift in IT toward performance, people who better understand performance, what drives it, and how to improve it are more valuable to their organizations.
- Share performance dashboards. Take credit for the performance improvements you achieve. Educate management about the cost savings resulting from reclaimed hardware or delayed investments. Share performance data. Be the authority. Report the performance impact and improvement (or not) of each infrastructure component and team member. Using your performance data, you can say, “Joe, the code you wrote this week sucks. It’s 25% slower than last week’s. Here’s the data.”
- Plan performance changes. You’ll know you have performance certainty when you can accurately predict application performance before changes occur and when you can guide your organization toward better performance.

Making Sure Performance Is Guaranteed
If you were to mention how performance certainty is harder to guarantee than uptime in a meeting, you’d most likely get eyes rolling from the crew taking it for granted. Actionable advice is a better proposition. And because management won’t really need to see the code (just how effective it is), a visual performance interface is crucial.
Without reading this article out loud to everyone concerned, most of the steps suggested above can be made a reality through the use of a tool like SolarWinds® Database Performance Monitor.
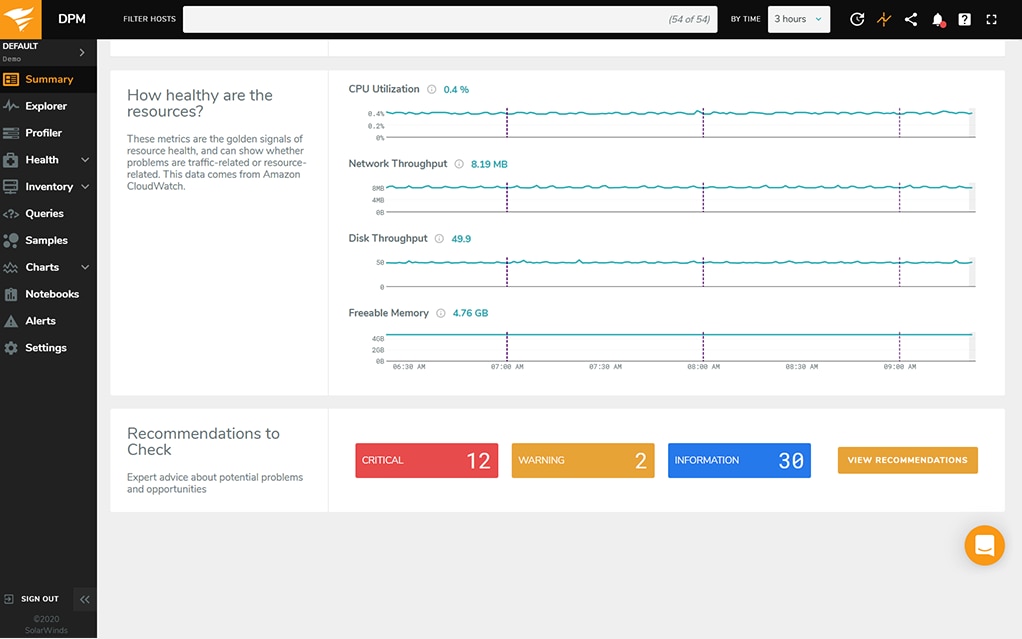
Some of the features of DPM include the following:
- Database Health Monitoring—A real-time peek into how your databases are performing in terms of faults, events, and indexes. Keeping tabs on how healthy a database is in real time can allow your team to employ best practice procedures and maintain near-perfect performance and uptimes. If your database crashes when no one’s watching, the historical data you can extract from DPM can help you perform audits and create plans to avoid the same issues in the future.
- Continuous Deployment Insights—Seeing how most software is getting continuously updated, you can measure the new code’s impact on the database with Database Performance Monitor. This can translate to better software deployment procedures with shorter times between software versions.
- Performance Optimization Through Visualization—DPM is built to monitor aspects of your database’s performance at a granular level, and it gives you the opportunity to take action instead of reacting to potential performance bottlenecks. The dashboard offers crucial analytics, so you can focus on the things capable of improving performance. With an overarching view of how each action affects your database, it’s much easier to have a high-performing product users will enjoy.
In summary, it’s all about the application. Performance is the new black. Performance certainty—knowing how a system will perform and how to fix it—will soon be a job requirement. Apart from making sure you have a firm handle on the overall performance of your system, a tool like SolarWinds Database Performance Monitor can make it easier to attain peak performance and keep an eye on the important metrics for DBAs and DevOps teams. I think it’s worth trying out the free trial of DPM or another solution to see how using a tool can help you more easily get key players on board once they see what’s been fixed, what needs to be fixed, and how it results in better performance.